2026-06-19 (2026-06-22 更新)
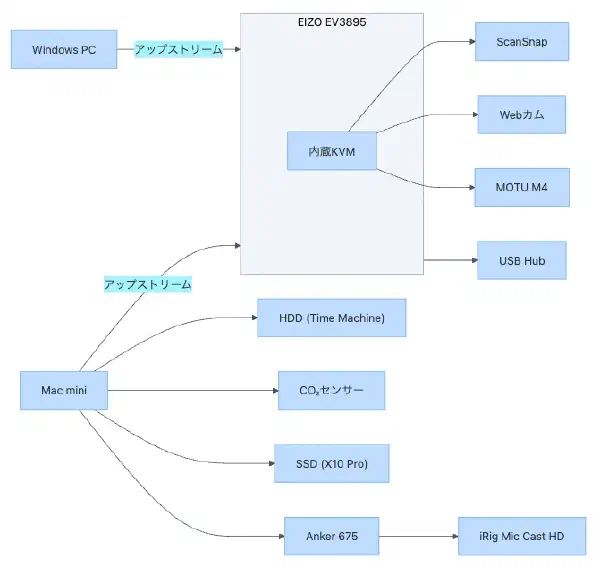
微妙に使いにくい部分があったが、面倒でずっと放置していたMacやWindows PCと周辺機器の接続を見直して結線し直した。
こういうのは書き残しておかないと、時間が経つとわからなくなるのでChatGPTにMermaidでダイアグラム化した。
graph LR subgraph EV3895["EIZO EV3895"] HUB["内蔵KVM"] end WIN["Windows PC"] -->|アップストリーム| EV3895 MAC["Mac mini"] -->|アップストリーム| EV3895 HUB --> SCAN["HHKB Studio"] HUB --> Slimblade["SlimBlade Pro "] HUB --> CAM["Webカム"] HUB --> MOTU["MOTU M4"] MAC --> ANKER["Anker 675"] ANKER --> IRIG["iRig Mic Cast HD"] ANKER --> BENQ["BENQ ScreenBar"] MAC --> HDD["HDD (Time Machine)"] MAC --> CO2["CO₂センサー"] MAC --> SSD["SSD (X10 Pro)"] 2026-06-22追記
自分の環境はBluetooth接続機器が多すぎるせいか、接続が安定しないのと、Macが完全にフリーズする事象が起きており、しばらくはキーボードとトラックパッドを優先接続で運用することにした(Slimbladeが怪しい気がしている)
C4モデルとは # ソフトウェアのアーキテクチャを表現するためのモデル。
コンテキスト(context) コンテナ(containers) コンポーネント(components) コード(code) で構成される。 C4モデルは特別な表記法を規定していない。以下、ダイアグラムの図はThe C4 model for visualising software architectureを参考に作成した。
flowchart TD ソフトウェアシステム:::system ソフトウェアシステム --> containerA(コンテナ) ソフトウェアシステム --> containerB(コンテナ) ソフトウェアシステム --> containerC(コンテナ) componentA1:::dot containerA:::dot --> componentA1(コンポーネント) componentA:::dot containerB --> componentA(コンポーネント) containerB --> componentB(コンポーネント) containerB --> componentC(コンポーネント) containerB:::container componentC:::dot componentA2:::dot containerC:::dot --> componentA2(コンポーネント) componentB --> codeA(コード) componentB --> codeB(コード) componentB --> codeC(コード) componentB:::component codeA:::code codeB:::code codeC:::code classDef dot fill:#eef,stroke:#f66,stroke-width:2px,color:#aaa,stroke-dasharray: 5 5 classDef system fill:#faa,stroke:#333,color:#fff,stroke-width:4px classDef container fill:#44f,stroke:#333,color:#fff,stroke-width:4px classDef component fill:#77f,stroke:#333,color:#fff,stroke-width:4px classDef code fill:#aaf,stroke:#333,color:#fff,stroke-width:4px レベル1 システムコンテキスト ダイアグラム # 対象システムが、それを使用する人や関連する他システムとの関係性、どのような位置づけにあるかを図示する。
terrastruct/d2: D2 is a modern diagram scripting language that turns text to diagrams. テキストからダイアグラムを生成するツール。類似のツールとしてはMermaid、GraphViz、PlantUMLなどがあり、以下のサイトでこれらのツールで同じダイアグラムを書く場合の比較が可能。このサイトはD2開発元によるものらしい。
Text to diagram テキストと出力の例 # 公式サイトからの引用
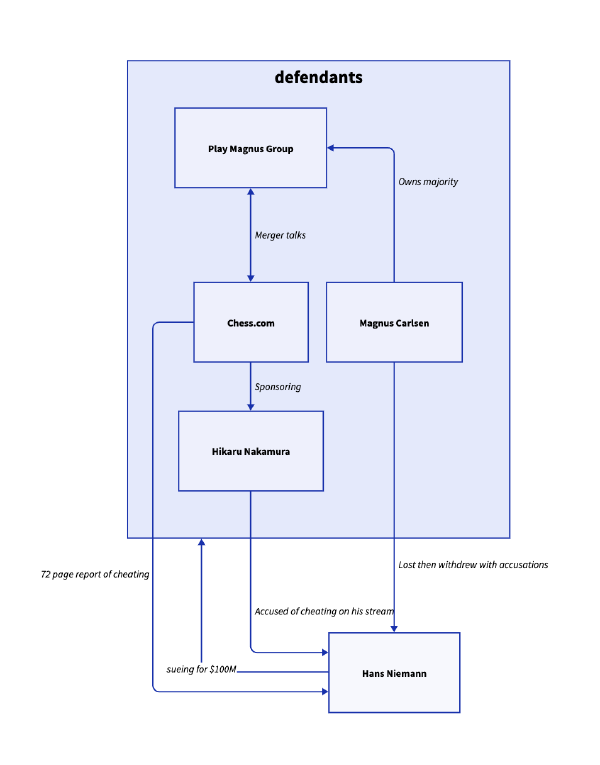
# Actors hans: Hans Niemann defendants: { mc: Magnus Carlsen playmagnus: Play Magnus Group chesscom: Chess.com naka: Hikaru Nakamura mc -> playmagnus: Owns majority playmagnus <-> chesscom: Merger talks chesscom -> naka: Sponsoring } # Accusations hans -> defendants: 'sueing for $100M' # Offense defendants.naka -> hans: Accused of cheating on his stream defendants.mc -> hans: Lost then withdrew with accusations defendants.chesscom -> hans: 72 page report of cheating インストール # d2/INSTALL.md at master · terrastruct/d2 Macの場合はbrew install d2でOK
利用シーン # 話が混乱したり、一方からの視点に偏った議論になった場合、二分割法で整理してみると良い。シンプルだが、メンバ全員がさまざまな意見を分析的に捕らえる手助けとなり、集中すべき方向性が見えてくる。
賛成・反対の理由を全員で共有する(プロ or コン) チームの意識を「可能なこと」に集中させる(制御可能 or 制御不能) そもそも論を排除して未来の議論に集中させる(過去 or 未来) 理想のイメージを整理しビジョンをつくる(モア or レス) 留意するポイント # 自分たちが制御できる問題か否かで分けて整理する。 制御できない問題は単なる愚痴になってしまうため、いくら話してもムダ。制御可能な問題を中心に議論するように方向付けする。
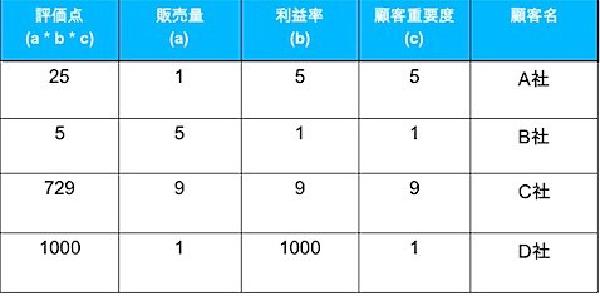
利用シーン # 複数の対象に対して優先度付けをしたい場合にに使用する。評価を行う観点を抽出した後、評価観点毎に点数を付け、それらの積を計算した評価点を用いて優先度を決定する。
点数は1,5,9のように離散値を設定し、その中から選ぶようにすると、中央付近の評価が集中し優先度を付けにくくなることを抑止できる。
また、人命や社命に関わるなど絶対に譲れない評価がある場合、最大点数^評価項目数(べき乗)を上回る特別点を設定できるようにする。(たとえば最高9点で3つの評価項目がある場合、9³=729点となるため特別点は1000点とするなど)
具体例 # 優先度を決定するための評価項目を検討する。重要な評価項目に漏れが生じないように慎重に検討すること。ここでは「販売量」「利益率」「顧客重要度」を設定した。 比較対象の名称を記述する。ここでは「A社」「B社」「C社」「D社」について比較を行っている。 設定した評価項目毎に議論し点数を記入する。 全ての項目に対して点数を記入したら評価点を計算する。評価点の大きいものから高い優先度で対応していく。
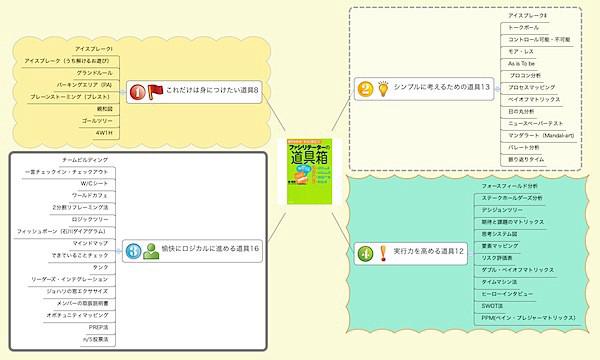
マインドマップは心理学者トニー・ブザンが開発した手法。真ん中に議論の中心になる言葉を書き、そこから放射線状に枝を伸ばし発想を展開していく。
利用シーン # ブレーンストーミングなど意見を発散したい場合に使うと効果的。増殖するマインドマップをみながら、発想のまま書いていくことにより、さらに新たな発想が生み出されていく。
会議ではホワイトボードの中心にテーマを書き、自由に意見を出してもらいながら枝に展開していく。できればイラストなどを入れてビジュアルしたり、枝の固まりを違う色で囲んだりして見ていて楽しいものにするとよい。
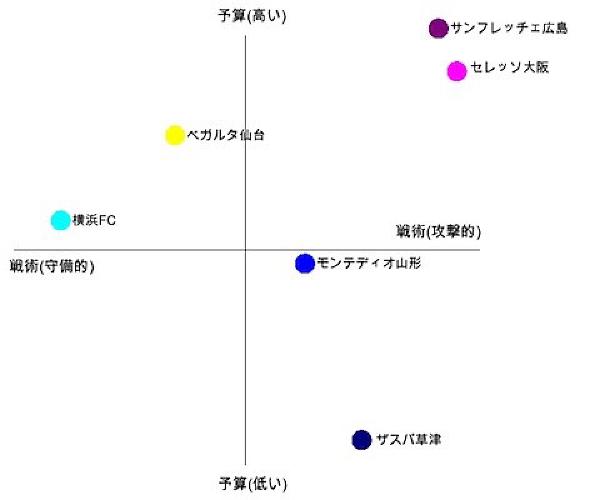
利用シーン # 新製品を開発する場合に、競合製品のポジションを評価し「空いている」ポジションをみつけるなど、複数の対象物のポジショニングを整理するために使う。
表記自体はペイオフマトリクスとあまり変わらない。ペイオフマトリクスは、ポジションを整理した後、優先度付けを行って案を選択するのに対して、ポジショニングマップは、ポジショニングを図示し、空いているポジションや進むべきポジションを検討するために使う。
具体例 # ポジショニングを評価するための基準を2つ設定する。ここでは「予算」と「戦術」を設定している。 全ての対象物をポジショニングマップ上へ位置付ける。 特に最初の対象物はどこに配置するか悩ましいが、とりあえずどこかへ配置する。 2つめ以降はそれまでに配置した物との相対的な関係を考慮しながら配置する。 あとから位置を動かしたくなることが多いため、ポストイットやマグネットなどを利用するとよい。
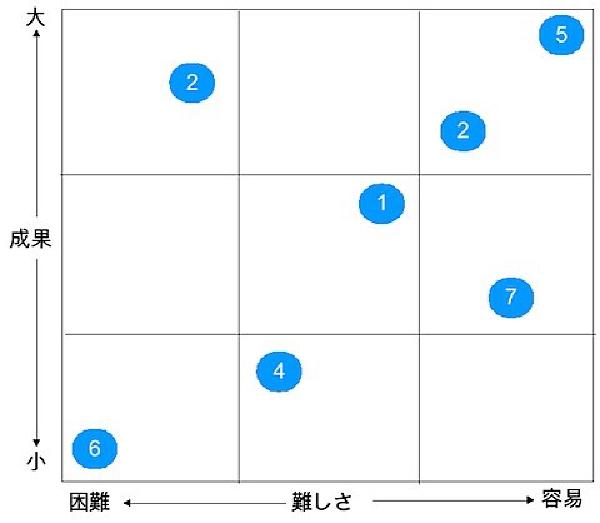
利用シーン # 複数の案の中から、どれを選べば良いのかで悩むことがある。そのような場合、2つの評価基準を設定し、ペイオフマトリクスで複数案の相対的ポジションを比較すると良い。
具体例 # あるテーマに対して議論し、複数の案を出す。 案を評価するために基準を2つ設定する。ここでは「成果」と「難しさ」を設定している。 全ての案をペイオフマトリクス上へ位置付ける。 特に最初の案はどこに配置するか悩ましいが、とりあえずどこかへ配置する。 2つめ以降の案はそれまでに配置した案との相対的な関係を考慮しながら配置する。 あとから位置を動かしたくなることが多いため、ポストイットやマグネットなどを利用するとよい。 全ての案を配置したら、(この場合は)右上のものから高い優先度を付けて4W1Hなどでアクションプランを作成し、実行する。
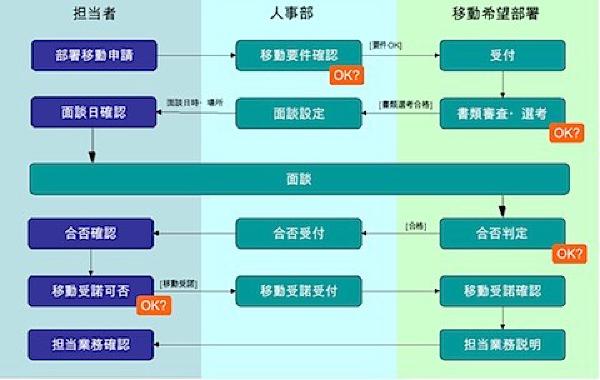
利用シーン # 業務プロセスのムダを見つけたい場合や、問題が発生しやすい作業フローを見つけたい場合に使用する。業務プロセスを見える化しブレーンストーミングすることで、それまでは「常識として疑わなかったが実はムダな作業やプロセス」をみつけやすくなる。
具体例 # 関連する部署を書き出し、それぞれの間に線を引く。ここでは「担当者」「人事部」「移動希望部署」を設定した。 業務プロセスを構成するタスクを抽出し1つの箱として表現する。 タスクの実行順序や流れはボックス間に矢印を書いて表現する。関係部署、タスク、実行順序を把握することが目的なので、特にフォーマットにはこだわらなくて良い。 プロセスマッピングが終わったら全体を俯瞰し、改善策をブレーンストーミングする。このとき、関連部署の出席者有無が議論の精度とスピードに大きな影響を与える。このため、極力、議論できる担当者に出席してもらえるよう、事前に各部署へ要請しておくと良い。
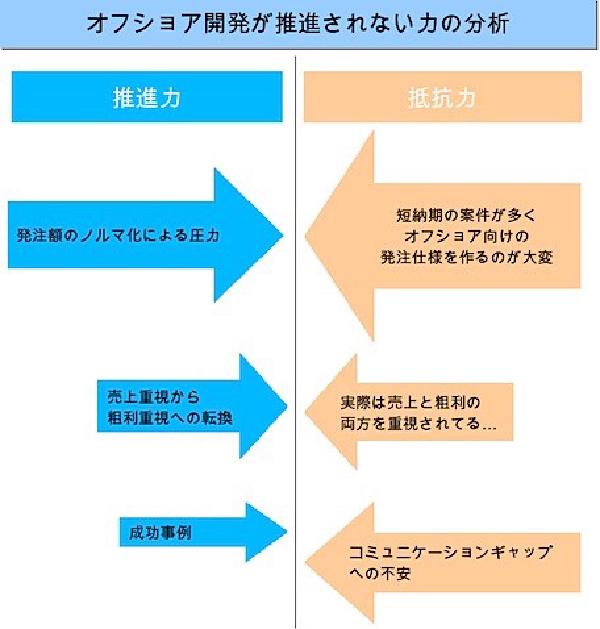
利用シーン # ある計画がうまくいっていない場合、その原因を人の心に作用する見えない力という視点で見える化し分析する。みんなの本音を見える化し、それぞれの力の強さを「推進力」「抵抗力」にまとめて全体を俯瞰することで、計画がうまくいかない理由を共有するとともに、改善策を検討するための論点を絞り込むことができる。
具体例 # 解決しようとするテーマを書き、その下を半分に分割し上の部分に「推進力」「抵抗力」と書く。ここでは解決しようとするテーマとして「オフショア開発が推進されない力の分析」を設定した。 ブレーンストーミングを行い、設定したテーマに対して推進する力、抵抗する力を書く。いかに本音を引き出せるかがポイント。 推進力、抵抗力ともに出そろったら、それぞれの「力」を矢印の大きさで表現する。最初の方は矢印の大きさを決めにくいが、とりあえず適当な大きさで書き、他の力との相対関係で調整する。 矢印の大きさで表現できたら、抵抗力を減少させるための方法についてブレーンストーミングする。 次に推進力を増加させるための方法、または新しい推進力が無いかブレーンストーミングする。 ブレーンストーミングした抵抗力を減少させる方法、推進力を増加させる方法が確実に実行されるよう、4W1Hなどを使ってアクションプランを作成しておく。
利用シーン # 議論が狭い視点での各論に陥った場合、オポチュニティマッピングを使って全体をビジュアルに表すことにより、議論対象の全体像が見えてくる。
オポチュニティマッピングにまとめる対象を決めたら、対象についての戦略を考える上で必要な切り口を検討し横軸を決める。縦軸と組み合わせ、それぞれのボックスの面積により、事業機会や売上高などの大きさを表すようにする。
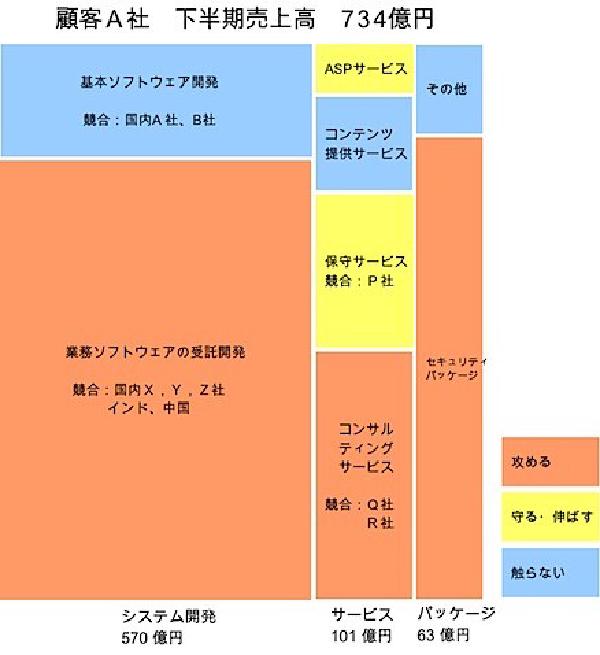
具体例 # 顧客A社の事業ドメインを横軸に展開する。ここではシステム開発、サービス、パッケージを設定する。 各事業ドメインの中の事業分野の大きさ(この例では売上高)を元に縦軸を設定する。この時、ボックスの面積が全事業における各事業分野の大きさを表すようにする。 この時、それぞれの大きさがわからない(公開されていない)場合があるが、その時は値を推定(仮説レベルでも良い)し、まずは書いてみる。その後、対象へのヒアリングや調査を通して、なるべく精度を高めていく。 マップが書けたら各事業分野の規模(ボックスの面積)や成長性、競合との関係などを加味し、戦略を立案する。 この例では「攻める」「守る・伸ばす」「触らない」という3つの優先度付けを行った。 オポチュニティマッピングを複数の関係者で作成することにより、対象の理解と戦略に関する共通認識が得られる。
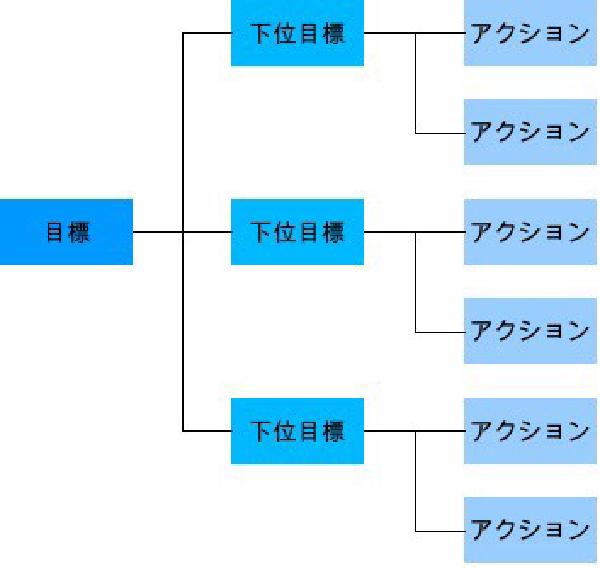
利用シーン # ゴールを明確化して発散した議論を収束する。 目的と手段を明確化する。 具体例 # 本質的な目標(ゴール)を定義する。例では「部門粗利10%アップ」を設定している。 目標を達成するための下位目標を定義する。下位目標の下にさらに下位目標があっても良い。 下位目標ごとに達成するために必要なアクションを定義する。 関連ツール # 4W1H # アクションまで決まるとなんとなく安心して、そのままにしてしまうことがある。アクションまで落とし込んだら、4W1Hで期限や担当者を明確にし、確実に実行される仕組みを作る。
WBS # 大きな目標に対するアクションは、さらに詳細なアクションへ分解しなければ実行しにくいケースがある。その場合、WBSを使ってアクションを詳細化し期限を設定する。
利用シーン # 組織(個人でも良い)の戦略を検討する際に、ブレストだけでは意見が発散してしまい、統一感のある戦略にまとめあげるのが難しいケースがある。そういう場合は、SWOT分析により論点を絞り意見を共有しながら戦略に落とし込むと良い。
具体例 # 自分たちの強み(Strength)と弱み(Weakness)について列挙する。分析対象を明確にした上で(全社、部、課など)ブレストの要領で行うと良い。 外部環境を機会(Opportunities)、脅威(Threats)に分けて列挙する。 いずれも、結論を出すためのプロセスではないことを注意する。ブレスト中、いつにまにか対策の議論に入ってしまうことがあるので注意。 上で列挙した強み・弱み・機会・脅威をマトリクスにして、それぞれについて今後、何をすべきかを議論する。 議論した「何をすべきか」が確実に実行されるよう、4W1Hなどを使ってアクションプランを作成しておく。
利用シーン # 目標に対して設定したアクションを具体化する。 責任分担を明確化し進捗状況をフォローする。 具体例 # 4W1HのうちWhereとHowは自明であることが多いためこの例では省略している。 「ステータス」は未着手・進捗率(パーセンテージ)・ペンディング・完了・中止などアクションの状態を表す語を定義し記述する。 「実施状況」はアクションの途中経過を日付入りで時系列に記述する。 定例会議でステータスの確認、進捗やアクションのアプローチに関するフォローアップを行うことで、確実にアクションを進める。(これが重要) 関連ツール # ゴールツリーで設定したアクションを実施する際に4W1Hを使用すると良い。
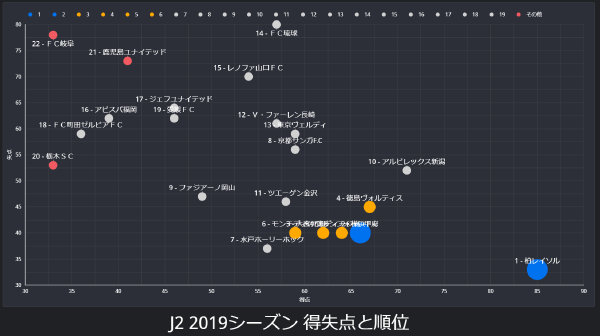
GoogleデータポータルでJ2 2019シーズンの得点失点と順位をバブルチャートにしてみた。
失点40前後のクラブ名が重なっていて読みづらいが、左から山形、大宮、甲府、横浜の順に並んでいる。
今シーズンのグラフを眺めていると、
得点が50点以上なら失点が多くても残留はできる 35点以下だと降格争い 柏は反則 が読み取れる。
いや~横浜はがんばったな。前回の昇格が2006年なので13年ぶりのJ1昇格ですよ。
2020シーズンは確実に厳しい1年になるだろうけど、楽しみたい!
前から気になっていたGoogle Data Studio(無償版)をJリーグのデータを見える化しつつ、試してみました。
Google Data Studioはデータをダッシュボードやレポートにまとめて、共有できるいわゆるBIツールです。できることは、大きく以下の4つ。
データソースへの接続 データの加工 データのビジュアライズ レポートの共有 データソースとしては、CSV/AdWords/BigQuery/Google Spanner/Google Cloud SQL/Google Cloud StorageGoogleアナリティクス/Googleスプレッドシート/MySQL/PostgreSQL/Search Console/Youtubeなどが公式にサポートされており、サードパーティー製のコネクターも用意されています。
基本的な流れとしては、
データソースを作成する。 使用するデータソースを指定し、レポートを作成する。 見える化したいデータをどう見せたいかに応じて必要なグラフをレポートへ貼り付ける。 グラフに対してデータソースのどのデータを使うか、どのキーでソートするかや、判例の表示有無、使用する色やフォントなどのスタイルを設定する。 必要な分だけ3〜4を繰り返す。 レポート上で各グラフの表示位置、サイズを調整。 という感じ。レポートは複数のページで構成可能です。
今回は2つのCSVファイルから2つのレポートを作成してみましが、操作方法は簡単で、ほとんどマニュアルを読まずになんとかなりました。
ただ、Google Data Studioは1つのレポートで接続できるデータソースが1つに限定され、ドリルダウン機能もないため、分析フェーズでは使いにくいかもしれません。
しかし、簡単に見栄えの良いレポートを作成して、素早く共有できるので、一般的な業務でのレポーティングにはかなり使えそうです。
今回作成したレポートは以下のURLから参照できますので、興味がある方はどうぞ。
2017年Jリーグディビジョン2 最終成績 2018年Jリーグ登録選手情報(少し表示に時間を要します) 横浜FCの得点6位、失点9位で10位に対し、長崎は得点7位で失点3位で2位か。やはり守備は重要ですなぁ…
群馬と名古屋がグラフ上の特異点になっている。町田はもう少し順位が上でも良さそうなポジション。
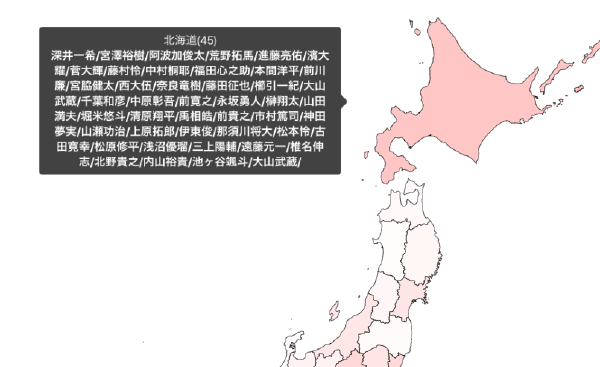
Jリーグ登録選手出身者マップ(2018)
Jリーグ登録選手ポジション別出身地(2018) FW/MFは神奈川県出身者がトップ。DF/GKは東京。攻撃的な神奈川。
Jリーグ登録選手生年別人数(2018) もっとも多いのが1995年生まれ。全体では1967年生まれから2002年生まれまでと幅広いですねぇ。35歳差ですよ…
D3.jsでJリーガーの出身地マップを作ってみました。
もっとも多いのは東京都の199人で、もっとも少ないのは高知県の1名でした。なかなかおもしろい。
出身の選手数が多いほど濃い色で表示され、マウスオーバーすると都道府県名・出身者数・選手名がツールチップで表示されます。
ソースコードはこちらです。プログラム的には、
TopoJSON形式の地図データ表示 複数JSONファイルの扱い(Promise.allを使用) 都道府県ごとのツールチップ設定(表示はTippy.jsを使用) d3.scaleLinearを用いた表示色の制御 などがトピックスでしょうか(というか、自分が勉強したことですが)
いくつかD3.jsでデータの見える化を試してみましたが、D3に食わせるデータを準備するところ、スクレイピングだったり、クレンジング、データの編集・加工などがいちばん大変かもしれません。(機械学習でも同じような苦しみがありますよね…)
以下は、地図情報の準備手順なのですが、まとまっておらず自分用の覚書です。
地図情報の準備(覚書) # 地形ファイルの入手 # 国土数値情報(日本限定、ライセンスに注意) http://nlftp.mlit.go.jp/ksj/index.html Natural Earth(世界全体、ライセンスフリー。ただし日本国土の国境の扱いが日本政府の方針と異なるケースがある) http://www.naturalearthdata.com/ http://www.naturalearthdata.com/http//www.naturalearthdata.com/download/10m/cultural/ne_10m_admin_1_states_provinces.zip 今回はNatural Earthのデータを利用(Admin 1 – States, Provinces)
GeoJSON形式への変換 # ShapeFileからGeoJSON形式に変換します。
関連ツールのインストール # npm install -g topojson brew install gdal brew install node Natural EarthからダウンロードしたShapefileは日本以外の情報も含まれており、GeoJSON形式へ変換する際に、データの絞り込みができるogr2ogrを使う。