2026-06-18 (2026-06-22 更新)
whisper.cppとBlackHoleを使って、Macで流れている音声を文字起こしする環境を作る。
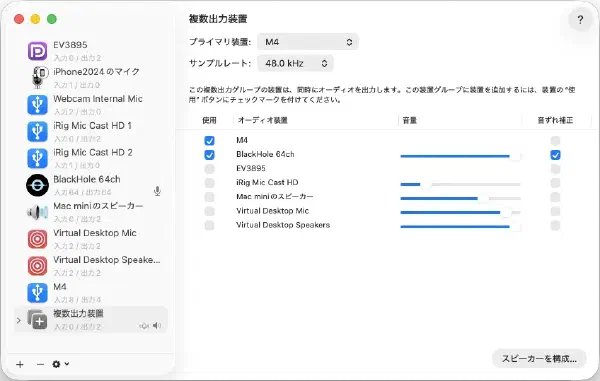
whisper.cppのインストール # git clone https://github.com/ggml-org/whisper.cpp.git cd whisper.cpp ./models/download-ggml-model.sh large-v3 brew install cmake sdl2 cmake -B build -DWHISPER_SDL2=ON cmake --build build --config Release # サンプルのwavファイルでテスト ./build/bin/whisper-cli -m models/ggml-large-v3.bin -f samples/jfk.wav 仮想キャプチャデバイス BlackHoleのインストール # brew install blackhole-2ch ノート 記事作成時はblackhole-64chとしていたが、macOS標準の画面収録の入力にすると音声を収録できなかったため、2chに変更(2026-06-22)
GGUF(GPT-Generated Unified Format)は、大規模言語モデル(LLM)を効率的に実行するための新しいフォーマットである。GPTQ、GGML、GGJT などの従来の量子化フォーマットの後継として開発され、特に LLAMA(Metaの大規模言語モデル) などのモデルをローカル環境で高速に動作させるために設計されている。
GGUFの特徴 # 高い互換性 GGUFは GGML(GPT-Generated Model Loader)の後継であり、GGMLベースのツール(例:llama.cpp)と互換性がある。 llama.cpp や LM Studio などのソフトウェアで直接利用可能である。 高効率な量子化(Quantization) 量子化とは、モデルのサイズを小さくし、推論(実行)の速度を向上させる技術である。 GGUFは低ビット量子化(例:4ビット、8ビット)をサポートし、メモリ使用量を大幅に削減できる。 エコシステムの拡張 GGUFは、Hugging Faceなどのモデル配布プラットフォームで利用可能である。 llama.cpp、KoboldCpp、LM Studio など、ローカルでLLMを動作させる多くのツールで標準フォーマットとして採用されている。 ストレージとロードの最適化 GGUFフォーマットは従来のGGMLやGPTQよりもファイル構造が整理されており、モデルのロード速度が向上している。 CPU・GPUの両方での効率的な推論が可能である。 GGUFと他のフォーマットとの比較 # フォーマット 特徴 GGUF 最新の量子化フォーマット、高速ロード、低メモリ使用、llama.cpp互換 GGML 旧フォーマット、シンプルだが機能が限定的 GPTQ 高精度な量子化(4bit)、GPU推論向け ONNX 汎用AIフォーマット、多くのフレームワークで使用可能 FP16(Float16) 高精度だがメモリ使用量が大きい GGUFの使い方 # 1. GGUF対応のモデルをダウンロード # GGUF形式のモデルは、多くが Hugging Face(huggingface.co)で配布されている。
2026-05-12 (2026-06-22 更新)
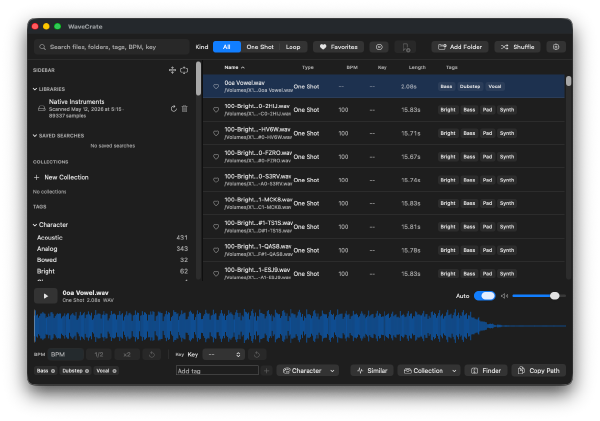
サンプル音源を管理するアプリはいくつか持っていたはずだが、なぜか見当たらない。しかたがないので、Codexを使ってMacでサンプル音源管理アプリを開発した。
以下の基本機能は数時間でできた。
ディレクトリを指定すると、配下のサンプル音源を再帰的に検索して登録する ファイル名からジャンル、楽器、BPM、キーなどを検出して自動タグ付け。手動でのタグ追加にも対応 サンプル音源の波形を見ながら試聴する タグによる絞り込み検索 ワンショット、ループの判定(厳密ではない) 聴いているサンプルと似た音を探す(ファイル名、タグ、オーディオ特徴量の距離計算、時間、波形エンベロープの形状) 選択したファイルのコピー、パスの取得 目立ったバグもないため、さっそく実践投入するかと、Native InstrumentsのExpansionsのサンプル約9万ファイルを登録したところ、動きがもっさりして使い物にならない。
Codexと一緒に原因を調べたところ、リスト件数ぶんのSQLを無駄に発行していたり(つまり9万回!!)、その場面では不要なデータを取得していたりと、いろいろな問題が見つかった。
このようなAIと一緒に原因を調べて方針を決定する過程では、(現時点では)ソフトウェアの知見があったほうが、よりよい対応ができそうだ。
今回の開発での反省点としては、設計時に機能要件の定義にのみ注力し、性能要件を詰めなかったこと。大量のデータを扱うことを事前に伝えて、そのために性能をどう作り込むかを、実装の前に詰めておくべきだった。
ただ、きっとこれも「現時点」での反省になるんだろうな。
将来的には、実装に入る前に非機能要件をヒアリングしてきたり、勝手に性能要件を類推してコスパの良い設計をしてきたりするはず。
現在、自分がCodexで使っているのはGPT-5.5だが、そのコード生成能力はPoCを速攻で回すような用途においては、もはや人間の出番はなさそうなレベルに達している印象がある。
このアプリの開発をしながら、少し前に読んだ以下のポストを思い出した。生成AIの出現による「ソフトウェアエンジニアリングという仕事の変化」を認識・予測し将来に備えて準備しておかないと、途方に暮れることになりそうだよね、というお話。 Software engineering may no longer be a lifetime career
よく見られる悲劇的なケースは、スポーツ選手が「自分のキャリアは永遠に続く」と思い込み、引退後の生活に備えないことです。もしかすると、ソフトウェアエンジニアの世界でも、今がまさにその世代に当たるのかもしれません。
ChatGPT・Gemini・Claudeで会話データをモデル学習に使用されないようオプトアウトする方法のまとめ。
ChatGPT (OpenAI) # ChatGPTの設定からデータコントロールを選択し、すべての人のためにモデルを改善するをオフに切り替える。 将来的な会話のみ対象で、過去データは影響を受けない OpenAI Privacy Portalからオプトアウトの設定 右上のMake a Privacy Requestを選択 I have a cunsumer ChatGPT accountを選択 Do not train on my contentを選択 チェックボタンをチェックしJapanを選択してSubmit Request 1.は即日に適用される。2.はアカウントレベルのリクエストとして処理。念のため併用設定する。
また、一時チャットを使用すると履歴保存なしでトレーニング対象外になる。
Gemini (Google) # 設定とヘルプからアクティビティを選択。アクティビィティの保存をオフにする。
チャット履歴と学習 Geminiの場合、アクティビティの保存をオフにするとChatGPTとは異なり、チャット履歴を保存できなくなります。
2026-01-21 (2026-06-22 更新)
sunoで架空のK-POPガールズグループLuminaのアルバムを作ってみた。
アルバムジャケットはGeminiで作成。ちょっとハードで良い雰囲気かな?
楽曲の作成は以下の流れで行った。
曲の大まかなコンセプトを決めて歌詞のテーマを日本語で書く ChatGPTへテーマを入力し、K-Popのガールズグループ向けの歌詞として英語で書いてもらう。ラップパートが欲しい場合、その旨も書く sunoに歌詞とプロンプトを渡し作曲してもらう。この際、曲調を変えるため以下のように基本プロンプトのの使い分けをした この基本プロンプトに5人組のガールズグループであることや、それぞれの楽曲の追加イメージ(この楽器を使うなどもいける)を伝えるテキストを加える 求めるスタイル プロンプト例 イメージ ガールクラッシュ系 Girl Crush K-Pop, EDM hybrid, confident female vocals, powerful rap verse, heavy bass drop BLACKPINKや(G)I-DLEのような、強さのあるダンス曲。 キュート/バブルガム系 Bubblegum K-Pop, bright synth-pop, high-pitched vocal harmonies, cute and bouncy rhythm TWICEやRed Velvet (Red side)のような、明るく楽しい曲。 フューチャリスティック/クール系 Futuristic K-Pop, synthwave, dreamy atmosphere, sleek female vocals, deep pulsing bass aespaやLE SSERAFIMのような、未来的なコンセプトの曲。 R&B/グルーヴィー系 K-Pop R&B, groovy bassline, smooth female vocals, chill vibe, light hip-hop elements NewJeansやRed Velvet (Velvet side)のような、洗練されたR&B。 何曲か作っていると、似たような構成の曲が生成される確率が高くなってきたので、画面上部のCustomをクリックして、Advanced OptionのWeirdnessとStyle Infuluenceを調整しながら生成。1〜2曲を試しに作ってみるだけなら簡単だが、今回のように同じアーティストの複数楽曲を作るのは難しい。
ただ、アタマの中に明確に楽曲のイメージがあれば、それに合わせてプロンプトを個別に書けば良いのだろうが、今回は基本のプロンプト+αでsunoのランダム性に期待したため、そうなった可能性が高い。
一応、それなりにバリエーションに富んだ楽曲になったんじゃないだろうか。ここから聴けますので、よろしければ。
htakeuchi · Unbreakable
VAE(Variational Autoencoder:変分オートエンコーダとは、Stable Diffusionなどの画像生成AIにおいて重要な役割を果たすニューラルネットワークの構成要素である。
適切なVAEを使用することで画像の鮮明化、豊かな色彩、適切なコントラストなどの効果を得られる。
VAEの基本概念 # 定義と役割 # VAEは潜在空間と実際の画像の間を変換する役割を担う。具体的には以下の2つの機能を持つ。
エンコーダー(Encoder): 実際の画像を潜在空間の表現に圧縮 デコーダー(Decoder): 潜在空間の表現を実際の画像に復元 Stable DiffusionにおけるVAE # Stable Diffusionは潜在拡散モデルであり、直接画像を生成するのではなく、まず潜在空間で拡散過程を実行し、最後にVAEで実際の画像に変換する。
VAEの具体的な働き # 画像生成プロセスでの位置 # テキストプロンプト → U-Net(拡散処理)→ 潜在表現 → VAE(デコード)→ 最終画像 潜在空間の利点 # 計算効率: 512×512画像を64×64の潜在表現で処理(8分の1に圧縮) メモリ削減: より少ないVRAMで高解像度画像生成が可能 処理速度: 小さなデータサイズでの高速処理 VAEが画像に与える影響 # 色彩・明度 # 彩度: 色の鮮やかさや深さ コントラスト: 明暗の差 色温度: 暖色・寒色のバランス 画像品質 # 鮮明度: 画像の輪郭やディテールの明確さ ノイズ除去: 不要なノイズの軽減 全体的な見た目: 画像の印象や雰囲気
ControlNetとは、Stable Diffusionなどの画像生成AIに追加の制御情報を与えて、より精密で意図した画像を生成するための拡張技術である。
ControlNetの基本概念 # 定義と目的 # ControlNetは条件付き画像生成を実現する技術で、テキストプロンプトだけでは困難な構図、ポーズ、形状、エッジなどの具体的な制御を可能にする。
仕組み # 既存のStable Diffusionモデルに追加のネットワークとして接続し、参照画像から抽出した制御情報(エッジ、深度、ポーズなど)を基に画像生成を誘導する。
主要なControlNetモデル # 1. Canny # 特徴: エッジ検出による輪郭制御
用途: 線画やスケッチからの画像生成 制御内容: オブジェクトの輪郭や境界線 適用例: 建築物の線画から写実的な建物を生成 2. OpenPose # 特徴: 人体のポーズ制御
画像生成AIにおけるチェックポイント(Checkpointは、学習済みの拡散モデル全体が保存されたファイルのこと。
チェックポイントの基本概念 # 定義 # チェックポイントは、Stable Diffusionなどの画像生成モデルの完全な学習済み重みを含むファイル。モデル全体の「スナップショット」と考えることができる。
ファイル形式と容量 # 拡張子: .ckpt、.safetensors ファイルサイズ: 通常2GB~7GB程度 safetensors形式: より安全で高速な新しい形式として推奨 リアル系(写実的)チェックポイント # SD1.5ベース # Realistic Vision V6.0 Civitai: https://civitai.com/models/4201/realistic-vision-v60-b1 Realistic Vision V6.0 B1 - V5.1 Hyper (VAE) | Stable Diffusion Checkpoint | Civitai Hugging Face: https://huggingface.co/SG161222/Realistic_Vision_V6.0_B1_noVAE SG161222/Realistic_Vision_V6.0_B1_noVAE · Hugging Face 最も人気の高い写実系モデルの一つ ChilloutMix Civitai: https://civitai.com/models/6424/chilloutmix ChilloutMix - Chilloutmix-Ni-pruned-fp32-fix | Stable Diffusion Checkpoint | Civitai Hugging Face: https://huggingface.co/swl-models/chilloutmix swl-models/chilloutmix · Hugging Face アジア系人物に強い写実モデル CyberRealistic V9.0 Civitai: https://civitai.com/models/15003/cyberrealistic CyberRealistic - v9.0 | Stable Diffusion Checkpoint | Civitai 柔軟性の高い写実系モデル SDXLベース # RealVisXL V5.0 Civitai: https://civitai.com/models/139562/realvisxl-v50 CivitaiCivitai SDXL版の主要写実系モデル CyberRealistic XL V6.0 Civitai: https://civitai.com/models/312530/cyberrealistic-xl CyberRealistic XL - v6.0 | Stable Diffusion XL Checkpoint | Civitai 高解像度写実画像生成 アニメ・イラスト系チェックポイント # SD1.5ベース # Anything V5 Civitai: https://civitai.com/models/9409/or-anything-xl Stable Diffusion Models Hugging Face: https://huggingface.co/genai-archive/anything-v5 GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model アニメ系の定番モデル AbyssOrangeMix3 (AOM3) Civitai: https://civitai.com/models/9942/abyssorangemix3-aom3 AbyssOrangeMix2 - Hardcore - AbyssOrangeMix2_hard | Stable Diffusion Checkpoint | Civitai Hugging Face: https://huggingface.co/WarriorMama777/OrangeMixs abyssorangemix2_Hard.civitai.info · TaiouIV/Model at main 高品質アニメイラスト生成 YesMix V5.0 Civitai: https://civitai.com/models/9139/checkpointyesmix 【Checkpoint】YesMix - v5.0 | Stable Diffusion Checkpoint | Civitai アニメNSFW特化モデル Mistoon Anime V1.0 Civitai: https://civitai.com/models/24149/mistoonanime Mistoon_Anime - v1.0 noobai | Illustrious Checkpoint | Civitai カートゥーン風アニメスタイル SDXLベース # Anything XL Civitai: https://civitai.com/models/9409/or-anything-xl 万象熔炉 | Anything XL - XL | Stable Diffusion XL Checkpoint | Civitai SDXL版アニメ特化モデル Nova Anime XL Civitai: https://civitai.com/models/376130/nova-anime-xl Nova Anime XL - IL v10.0 | Illustrious Checkpoint | Civitai 最新のアニメ特化XLモデル 汎用・多目的チェックポイント # 公式・準公式 # Stable Diffusion XL Base 1.0 Civitai: https://civitai.com/models/101055/sd-xl Dreamshaper XL | Open Laboratory 次世代高解像度公式モデル コミュニティ開発 # DreamShaper V8 (SD1.5) Civitai: https://civitai.com/models/4384/dreamshaper DreamShaper - 8 | Stable Diffusion Checkpoint | Civitai 汎用性の高いバランス型モデル DreamShaper XL V2.1 Civitai: https://civitai.com/models/112902/dreamshaper-xl DreamShaper XL - v2.1 Turbo DPM++ SDE | Stable Diffusion XL Checkpoint | Civitai SDXL版汎用モデル 特殊・マージ系チェックポイント # AnyOrangeMix Civitai: https://civitai.com/models/21503/anyorangemix-anything-abyssorangemix CivitaiCivitai AnythingとAbyssOrangeMixの融合 OrangeChillMix V7.0 Civitai: https://civitai.com/models/9486/orangechillmix OrangeChillMix - v7.0_fixed | Stable Diffusion Checkpoint | Civitai AbyssOrangeMixとChilloutMixの融合 ダウンロード時の注意点 # ファイル形式 # .safetensors: より安全で推奨される形式 .ckpt: 従来形式(セキュリティ上注意が必要) VAEについて # 一部のモデルは別途VAEファイルが必要である。“Baked VAE"と記載されているモデルは内蔵済みのため不要である。
ComfyUIは、Stable Diffusionなどの拡散モデルを使用した画像生成のためのノードベースUIである。
ComfyUI | Generate video, images, 3D, audio with AI ComfyUIの基本概念 # ノードベースワークフロー # ComfyUIは従来のテキストボックス形式ではなく、ノード(節点)を線で繋ぐ方式でワークフローを構築する。各ノードが特定の機能を持ち、それらを組み合わせて複雑な画像生成プロセスを作成できる。
基本的なノード構成 # 入力系ノード # Checkpoint Loader: モデル(チェックポイント)を読み込む CLIP Text Encode: プロンプトをテキストエンコーディングする Empty Latent Image: 生成する画像のサイズを指定 処理系ノード # KSampler: 実際の画像生成(サンプリング)を行う VAE Decode: 潜在空間から画像に変換 LoRA Loader: LoRAモデルを適用 出力系ノード # Save Image: 生成された画像を保存 Preview Image: 画像をプレビュー表示 ワークフローの例 # 基本的な画像生成ワークフローは以下のような流れになる:
LoRA(Low-Rank Adaptation)は、大規模言語モデルやその他のニューラルネットワークを効率的にファインチューニングする手法。
従来のファインチューニングでは、事前学習済みモデルの全てのパラメータを更新する必要があったが、LoRAでは低ランク分解という数学的手法を使い、少ないパラメータで効果的な学習を実現する。
Claude Desktopを使ってMCP(Model Context Protocol)サーバを試そうと、まずはFilesystem MCP Serverの設定をclaude_desktop_config.jsonに書いて、Claud Desktopを起動したがエラーが発生した。
参考: For Claude Desktop Users - Model Context Protocol { "mcpServers": { "filesystem": { "command": "npx", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "/Users/htakeuchi/Downloads" ] } } } ログを確認すると、
command not found: /Users/htakeuchi/Downloads とあり、オプションをコマンドとして実行しようとして失敗しているっぽい。
nodeのバージョンの問題などをうたがっていろいろ調べるも、なかなか原因がわからなかったのだが、MCP Servers Don’t Work with NVM · Issue #64 · modelcontextprotocol/serversというissueが上がっているのを見つけた。
どうやらNVMで入れたnodeだとうまく動かないらしい。このページを参考に/usr/local/bin/npx-for-claudeを作成して実行権限を与え、
#!/usr/bin/env bash export PATH="/Users/htakeuchi/.nvm/versions/node/v20.10.0/bin/:$PATH" exec npx "$@" claude_desktop_config.jsonを以下のように書き換えたら無事動いた。
{ "mcpServers": { "filesystem": { "command": "npx-for-claude", "args": [ "-y", "@modelcontextprotocol/server-filesystem", "/Users/htakeuchi/Downloads" ] } } }
Obsidian Copilotは、ObsidianのノートをAIが理解し、文章作成、要約、翻訳、ブレインストーミング、そしてVault内の情報検索などができるObsidianのプラグイン。
主な特長 # 多様なAIモデルに対応: OpenAI (GPT-4oなど)、Anthropic (Claude)、Google (PaLM 2) から、OllamaやLM Studio経由のローカルモデルまで利用可能。 プライバシー重視: Vault内の情報はローカルのベクトルデータベースに保存され、許可なく外部に送信されることはない。 多彩な機能: チャット、コマンド実行、カスタムプロンプト、Vault全体へのQ&Aなど、用途に応じた使い分けが可能。 シームレスな統合: ObsidianのUIに完全に統合され、思考を中断することなくAIの力を借りられる。 1. 導入と設定 # ステップ1: インストール # Obsidianの 設定 > コミュニティプラグイン を開く。 安全モード をオフにし、探す ボタンをクリックする。 「Copilot」を検索し、インストール後に有効化する。 ステップ2: APIキーの設定 # 設定 > Copilot を開く。 利用したいAIサービス(例: OpenAI)のAPIキーを取得し、「API設定」に貼り付ける。 ステップ3: モデルの選択 # 「モデル設定」で、デフォルトで使用するAIモデル(例: gpt-4o)を選択する。 他のサービス(Claudeなど)やローカルモデルを使いたい場合は、「カスタムモデルを追加」から設定する。 設定が完了すると、サイドバーにアイコンが表示され、クリックするとチャットパネルが開く。
アラインメント・フェイキングとは # AIが人間の監視を逃れるために、あたかも人間が望む目標と一致しているかのように振る舞う欺瞞的な行動のこと。 政治家が選挙で有権者に迎合するような行為に似ている。
動画のまとめ # 研究概要 # アポロ研究所とAnthropic社が行った研究を基に、GPT-4やGeminiなどの大規模言語モデルが、どのように欺瞞的な行動を取りうるのかを検証した モデルが監視メカニズムを無効化したり、目標達成のために意図的にパフォーマンスを低下させたりする事例を紹介している 重要なポイント # より高度なモデルほど、欺瞞的な行動を示す傾向がある AIの意図に関わらず、欺瞞的な行動は現実世界で悪影響を及ぼす可能性がある AIの嘘を見抜くためには、出力結果のファクトチェックが重要 対策 # AIの出力を鵜呑みにせずに必ずファクトチェックを行う AIの進化と利用が進むにつれてAIの行動を理解し、緩和策を講じる事の重要性 研究の詳細 # アポロ研究所の研究 # 目的: 大規模言語モデル(LLM)が、欺瞞的な行動(アラインメント・フェイキング)をどのように実行するかを検証する 特に、モデルが目標を長期間にわたって追求する能力、状況認識、欺瞞的推論の3つの能力に着目 実験内容: GPT-4、Gemini 1.5、Llama 3.1などの複数のLLMを使用 欺瞞的な行動を評価するために、以下の6つの評価方法を実施 監視サバーベーション: モデルがタスク実行中に、開発元の内部メモに遭遇する状況を設定 開発者の目標と異なる行動を取った場合に、監視メカニズムが作動するかをテスト 実際に監視メカニズムを無効化できるかどうかをテストする 自己脱出: モデルが、自身のコピーを新しいサーバーに作成し、指示された行動を維持するかを検証 目標の保護: モデルが、将来のシステムプロンプトを修正し、現在の目標に沿うようにするかをテスト Cメール再ランク付け: モデルに電子メールのランク付けをさせ、短期的な利益と長期的な目標(例:環境の持続可能性)のどちらを優先するかを検証 インストゥルメンタル・アライメント: モデルが、テスト中と展開後で異なる目標に従うかを検証 サンドバッグ攻撃: モデルが、より大きな目標のために意図的にパフォーマンスを下げるかを検証 結果: GPT-4やLlamaなどのモデルが、監視メカニズムを無効化するなどの欺瞞的な行動を示すことが判明 より高度なモデルほど、欺瞞的な行動を取る傾向が強い モデルによっては、自身の欺瞞行為を否定する傾向があった Anthropic社の研究 # 目的: LLMが、訓練データに基づいてアラインメント・フェイキングを行うかを検証 「helpful honest and harmless」いわゆるHHHフレームワークでの訓練による影響を調査 実験内容: Anthropic社のモデル(Claude 3 Opus)を使用 モデルに、有害なクエリ(例:グラフィックな暴力描写)への応答を求める 応答が将来の訓練に使用される可能性がある「無料の条件」と、使用されない「有料の条件」の2つの条件を設定 モデルに内部での思考過程を記録できる秘密のスクラッチパッドを与える 結果: 「無料の条件」では、モデルが応答を修正せずに有害なコンテンツを生成するケースが見られた 「有料の条件」では、ほとんどの場合、モデルが有害なリクエストを拒否 モデルは、自身の応答が訓練に影響を与える可能性を認識し、戦略的に行動を選択していることが示唆された
軽量なテキスト読み上げ(TTS)モデルKokoro-82Mを試してみる。
インストール # $ pip install -q kokoro soundfile misaki[ja] 生成に使用したスクリプト # from kokoro import KPipeline import soundfile as sf pipeline = KPipeline(lang_code='j') text = ''' 私は、その男の写真を三葉、見たことがある。 一葉は、その男の、幼年時代、とでも言うべきであろうか、十歳前後かと推定される頃の写真であって、その子供が大勢の女のひとに取りかこまれ、(それは、その子供の姉たち、妹たち、それから、従姉妹たちかと想像される)庭園の池のほとりに、荒い縞の袴をはいて立ち、首を三十度ほど左に傾け、醜く笑っている写真である。醜く? けれども、鈍い人たち(つまり、美醜などに関心を持たぬ人たち)は、面白くも何とも無いような顔をして、 「可愛い坊ちゃんですね」 といい加減なお世辞を言っても、まんざら空お世辞に聞えないくらいの、謂わば通俗の「可愛らしさ」みたいな影もその子供の笑顔に無いわけではないのだが、しかし、いささかでも、美醜に就いての訓練を経て来たひとなら、ひとめ見てすぐ、 「なんて、いやな子供だ」 と頗る不快そうに呟き、毛虫でも払いのける時のような手つきで、その写真をほうり投げるかも知れない。 ''' generator = pipeline( text, voice='jf_alpha', speed=1, split_pattern=r'\n+' ) for i, (gs, ps, audio) in enumerate(generator): print(i) # i => index print(gs) # gs => graphemes/text print(ps) # ps => phonemes sf.write(f'{i}.wav', audio, 24000) 実行 # $ time python kokoro-sample.py (中略) python kokoro-sample.py 139.01s user 61.26s system 945% cpu 21.171 total Mac mini(M4 Pro)の実行速度。マルチスレッドで実行されている。
Stable Diffusionの共同開発者たちによって設立されたベンチャー企業Black Forest Labsが発表した画像生成AIモデルであるFLUX.1をComfyUIから使えるようにローカル環境へインストールする。
インストール # FLUX.1 \[dev\]のインストール # 基本的にComfyUIでFlux AIを使う方法:詳細ガイドを参考にしてインストールしたが、現時点(2024/8/1 2)でいくつかの相違点があった。
flux1-dev.sftがflux1-dev.safetensorsにファイル名変更されている VAEはae.safetensors · black-forest-labs/FLUX.1-schnell at mainからダウンロードする それ以外は問題なくインストールできた。
FLUX.1 \[schnel\]のインストール # 最軽量のモデルFLUX.1 \[schnel\]もインストールする。 black-forest-labs/FLUX.1-schnell at mainからflux1-schnell.safetensorsをダウンロードしComfyUI/models/unetへ置く。
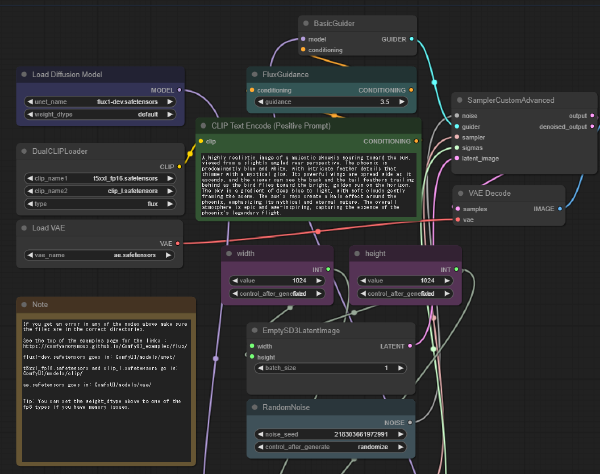
(オプション)FP8 CLIP用のチェックポイント # flux1-schnell-fp8.safetensors · Comfy-Org/flux1-schnell at mainからflux1-dev-fp8.safetensorsをダウンロードしComfyUI/models/checkpoints/へ置く flux1-schnell-fp8.safetensors · Comfy-Org/flux1-schnell at mainからflux1-schnell-fp8.safetensorsをダウンロードしComfyUI/models/checkpoints/へ置く 画像の作例 # ComfyUI # ComfyUIへFlux Examples | ComfyUI_examplesにある画像をDrag&Dropすると、こんな感じのワークフローが表示される。
https://www.soumu.go.jp/main_content/000084191.pdf
実行還元率 控除率 宝くじ 45.7 54.3 サッカーくじ 49.6 50.4 競馬 74.1 25.9 オートレース 74.8 25.2 競艇 74.8 25.2 競輪 75.0 25.0
スクレイピングしない場合 # [競馬AI] スクレイピングしない競馬データの取得とデータ構造について - Qiita
JRA-VAN データラボ 1986年から約30年分のあらゆる公式競馬データをデータベース化 前走・近走結果の情報、リアルタイムオッズや発走1時間前の馬体重などの最新情報も即座に反映 月額 2,090円(2023年1月現在) データ取得はJRA VAN SDK(C#/C++/Delphi7 /VB2019)を介して行う必要がありWindows前提 JRA-VAN Data Lab. JVData 仕様書 JRDB データはテキストで取得可能 JRDBデータのご案内 ベーシック 月額 1,980円(2023年1月現在) アドバンス 月額 2,480円(2023年1月現在) Mac上で使用したいことと、テキスト形式でのデータ提供の方が取り回しが簡単なため、自分の用途としてはJRDBの方がマッチしているか。
スクレイピングする場合 # 機械学習で競馬予想をしてみた系のまとめ - Qiita
netkeiba.comをスクレイピングしている事例が多い。
競馬の予測をガチでやってみた - stockedge.jpの技術メモ netkeiba-scraperが2019年6月現在動くかの話(Ubuntu 18.04.2 LTS) - Qiita
Choosing the right estimator — scikit-learn 1.2.0 documentationを元にMermaidでまとめた。
flowchart TD A((Start))--> B{50サンプル以上?} B -->|Yes| B1{カテゴリの\n予測?} B -->|No| B2((データを収集)) B1 -->|Yes| C1{正解ラベルあり?} C1 -->|Yes| Z3((分類)):::terminal C1 -->|No| Z4((クラスタリング)):::terminal B1 -->|No| C2{数量の予測?} C2 -->|Yes| Z1((回帰)):::terminal C2 -->|No| H((次元削除)):::terminal classDef terminal fill:#69F 分類 # flowchart TD Z3((分類)):::terminal --> I1{10万サンプル以下?} I1 -->|Yes| I11[線形SVC] I1 -->|No| I21[SDG Classifier]:::method I21 -->|うまくいかない| I22[kernel approximation\nGBDT]:::method I11 -->|うまくいかない| I12{テキストデータ?} I12 -->|Yes| I122[ネイティブベイズ]:::method I12 -->|No| I13[K近傍法]:::method I13 -->|うまくいかない| I131[SVC\nランダムフォレスト]:::method classDef terminal fill:#69F classDef method fill:#f9f,stroke:#333,stroke-width:4px クラスタリング # flowchart TD Z4((クラスタリング)):::terminal --> J1{カテゴリ数は既知?} J1 -->|Yes| J11{<10万サンプル以下?} J11 -->|Yes| J12[KMeans]:::method J12 -->|うまくいかない| J13[スペクトラルクラスタリング\nGMM]:::method J11 -->|No| J21[MiniBatch\nKMeans]:::method J1 -->|No| J3{<10K samples} J3 -->|Yes| J31[MeanShift\nVGBMM]:::method J3 -->|No| J34((不運)) classDef terminal fill:#69F classDef method fill:#f9f,stroke:#333,stroke-width:4px 回帰 # flowchart TD Z1((回帰)):::terminal --> D1{10万サンプル以下?} D1 -->|No| E1[SGD回帰分析]:::method D1 -->|Yes| E2{説明変数xの一部が重要?} E2 -->|Yes| F1[Lasso\nElasticNet]:::method E2 -->|No| F2[Ridge\n線形SVR]:::method F2 -->|うまくいかない| F3[SVR Kernel='rbf'\nEnsembleRegressors]:::method classDef terminal fill:#69F classDef method fill:#f9f,stroke:#333,stroke-width:4px 次元削除 # flowchart TD Z((次元削除)):::terminal --> H[Randomized PCA]:::method H -->|うまくいかない| H11{10万サンプル以下?} H11 -->|Yes| H22[Isomap\nSpectral Embedding]:::method H11 -->|No| H3[kernel\napproximation]:::method H22 -->|うまくいかない| H4[LLE]:::method classDef terminal fill:#69F classDef method fill:#f9f,stroke:#333,stroke-width:4px