azooKeyという高精度なニューラルかな漢字変換エンジンをサポートしたiOS用キーボードアプリのmacOS版を試している。
ライブ変換もサポートしていて、標準のIMEより変換精度が高くて素晴らしい。問題なく常用できそうな感じ。
ただ、いくつかのIMEでサポートしている「きょう」で本日の日付に変換する機能がないんですよね。これはXでも話題になっていて、以下のような改善策も見つけました。
azooKey-Desktop で日付を入力する - terfnoのScrapbox
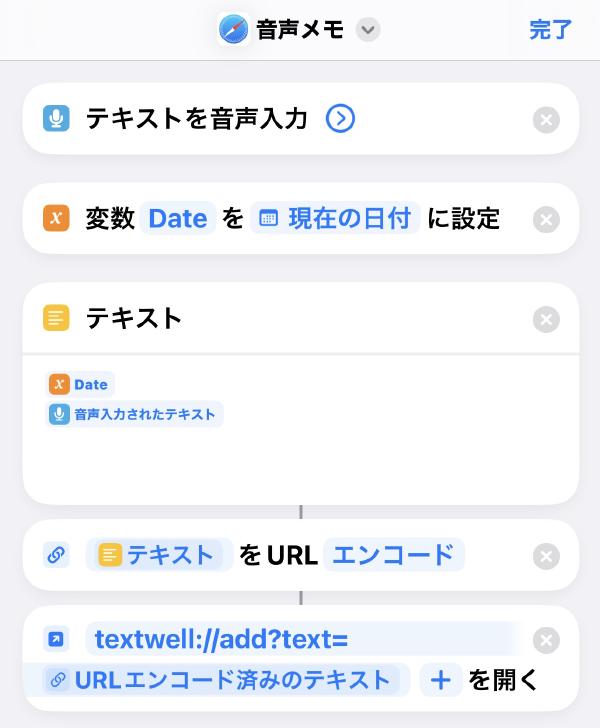
しかし、個人的には「昨日」や「明日」「先週の金曜日」などの日付を得たいケースが多く、ChatGPTでAlfred用のワークフローを作成した。
動作イメージ#
ワークフローを起動して、キーワードを入力すると対応するものがサジェストされる。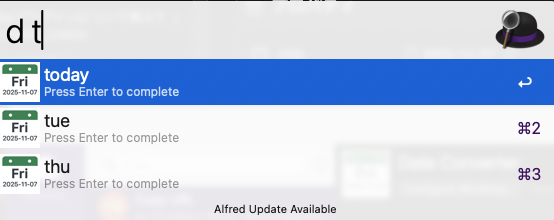
キーワードを決定すると、複数の日付フォーマットを選択できる。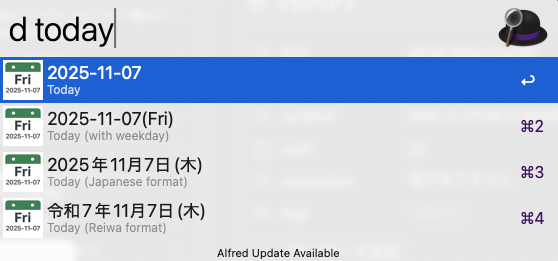
対応キーワード#
today:今日yesterday:昨日tomorrow:明日dayaftertomorrow(略:dat):明後日daybeforeyesterday(略:dby):一昨日mon/tue/wed/thu/fri/sat/sun:各曜日- 曜日を入力した場合は 「直近の過去の同曜日」「次に来る同曜日」を候補に表示
出力フォーマット#
- ISO形式:
YYYY-MM-DD - ISO + 曜日:
YYYY-MM-DD(Fri) - 日本語形式:
YYYY年M月D日(金) - 和暦形式(令和):
令和X年M月D日(金)
ダウンロード#
作成したワークフローを置いておきます。Alfred 5.7で動作確認しました。
しかし、この手の「自分専用のちょっとしたツール」をつくるのに生成AIは最高ですね😄