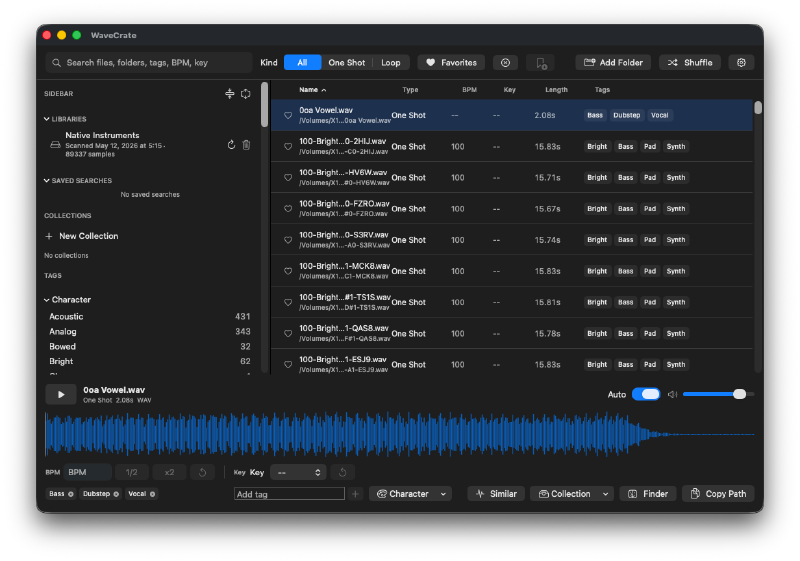
以下の基本機能は数時間でできた。
- ディレクトリを指定すると、配下のサンプル音源を再帰的に検索して登録する
- ファイル名からジャンル、楽器、BPM、キーなどを検出して自動タグ付け。手動でのタグ追加にも対応
- サンプル音源の波形を見ながら試聴する
- タグによる絞り込み検索
- ワンショット、ループの判定(厳密ではない)
- 聴いているサンプルと似た音を探す(ファイル名、タグ、オーディオ特徴量の距離計算、時間、波形エンベロープの形状)
- 選択したファイルのコピー、パスの取得
目立ったバグもないため、さっそく実践投入するかと、Native InstrumentsのExpansionsのサンプル約9万ファイルを登録したところ、動きがもっさりして使い物にならない。
Codexと一緒に原因を調べたところ、リスト件数ぶんのSQLを無駄に発行していたり(つまり9万回!!)、その場面では不要なデータを取得していたりと、いろいろな問題が見つかった。
このようなAIと一緒に原因を調べて方針を決定する過程では、(現時点では)ソフトウェアの知見があったほうが、よりよい対応ができそうだ。
今回の開発での反省点としては、設計時に機能要件の定義にのみ注力し、性能要件を詰めなかったこと。大量のデータを扱うことを事前に伝えて、そのために性能をどう作り込むかを、実装の前に詰めておくべきだった。
ただ、きっとこれも「現時点」での反省になるんだろうな。
将来的には、実装に入る前に非機能要件をヒアリングしてきたり、勝手に性能要件を類推してコスパの良い設計をしてきたりするはず。
現在、自分がCodexで使っているのはGPT-5.5だが、そのコード生成能力はPoCを速攻で回すような用途においては、もはや人間の出番はなさそうなレベルに達している印象がある。
このアプリの開発をしながら、少し前に読んだ以下のポストを思い出した。生成AIの出現による「ソフトウェアエンジニアリングという仕事の変化」を認識・予測し将来に備えて準備しておかないと、途方に暮れることになりそうだよね、というお話。
Software engineering may no longer be a lifetime career
よく見られる悲劇的なケースは、スポーツ選手が「自分のキャリアは永遠に続く」と思い込み、引退後の生活に備えないことです。もしかすると、ソフトウェアエンジニアの世界でも、今がまさにその世代に当たるのかもしれません。