whisper.cppとBlackHoleを使って、Macで流れている音声を文字起こしする環境を作る。
whisper.cppのインストール#
git clone https://github.com/ggml-org/whisper.cpp.git
cd whisper.cpp
./models/download-ggml-model.sh large-v3
brew install cmake sdl2
cmake -B build -DWHISPER_SDL2=ON
cmake --build build --config Release
# サンプルのwavファイルでテスト
./build/bin/whisper-cli -m models/ggml-large-v3.bin -f samples/jfk.wav仮想キャプチャデバイス BlackHoleのインストール#
brew install blackhole-2chノート
記事作成時はblackhole-64chとしていたが、macOS標準の画面収録の入力にすると音声を収録できなかったため、2chに変更(2026-06-22)
Macで再生されている音声を文字起こしするために必要な、仮想キャプチャデバイスBlackHoleをインストールする。
インストール後、Macを再起動して、Audio MIDI設定アプリを起動する。
複数出力装置を作成し、M4とBlackHole 2chをチェックする。
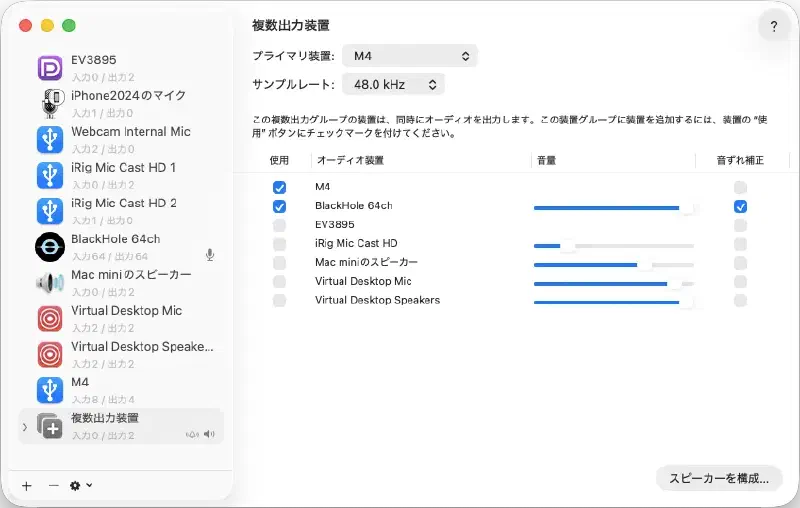
私の環境ではスピーカーを接続しているオーディオインタフェースM4とBlackHole 2chを指定している。
その後、Macの音声出力先を複数出力装置に設定する。これで、スピーカーで音声を再生しながら、BlackHoleへも音声を流すことができる。
Macのサウンド設定#
設定 > サウンド > 出力にさきほど作成した複数出力装置を指定し、入力はBlackHole 2chを設定する。
whisper-streamで文字起こし#
あとは、ターミナルから以下のコマンドでMacで再生されている音声を文字起こしできる。
build/bin/whisper-stream -m models/ggml-large-v3.bin -l ja -t 8 --step 5000 --length 5000 -kc --capture 2--captureオプションで指定している数字は、オーディオキャプチャデバイスの番号だ。
これは、一度、whisper-streamを動かせば、SDL2が認識しているオーディオキャプチャデバイスと番号がリストされるので、Black Holeに割り当てられた番号を指定すればOK